FORDYPNING
Metadata – de skjulte perlene i dokumentene
Metadata er en av de viktigste byggesteinene i dokumentasjonsforvaltning, og uten metadata hadde vi egentlig ikke fått til så veldig mye. Kanskje en av de store forskjellene mellom det å ha dokumentasjon på papir og elektronisk er hvordan det er lagt til rette for bruken av metadata.
En kan på en måte se på et arkiv- eller fagsystem som et dokumentlager med tilhørende metadata som kan brukes til å forvalte dokumentasjon. Metadata kan danne kontekst, struktur, prosess, autentisitet og kan være et utgangspunkt for tilgangskontroll og søk. Vi kan trygt si at kjernen i dokumentasjonsforvaltning er metadata. Går vi litt dypere, er det også mulig å vurdere dokumentene i dokumentsamlingen og hvilke metadata som støttes der, og det er det vi skal gjøre her.
Metadata i Word
Microsoft Word er et tekstredigeringsprogram som ofte brukes av forvaltningen. Her lagres innhold som docx. En docx-fil har et relativ rikt omfang av metadata som kan fortelle en del interessante ting om dokumentet. Programmet legger automatisk til metadata i docx-filer, og disse er ofte ukjent eller usynlig for brukeren. Tabell 1 viser noen av metadata-elementene som støttes av dette formatet.
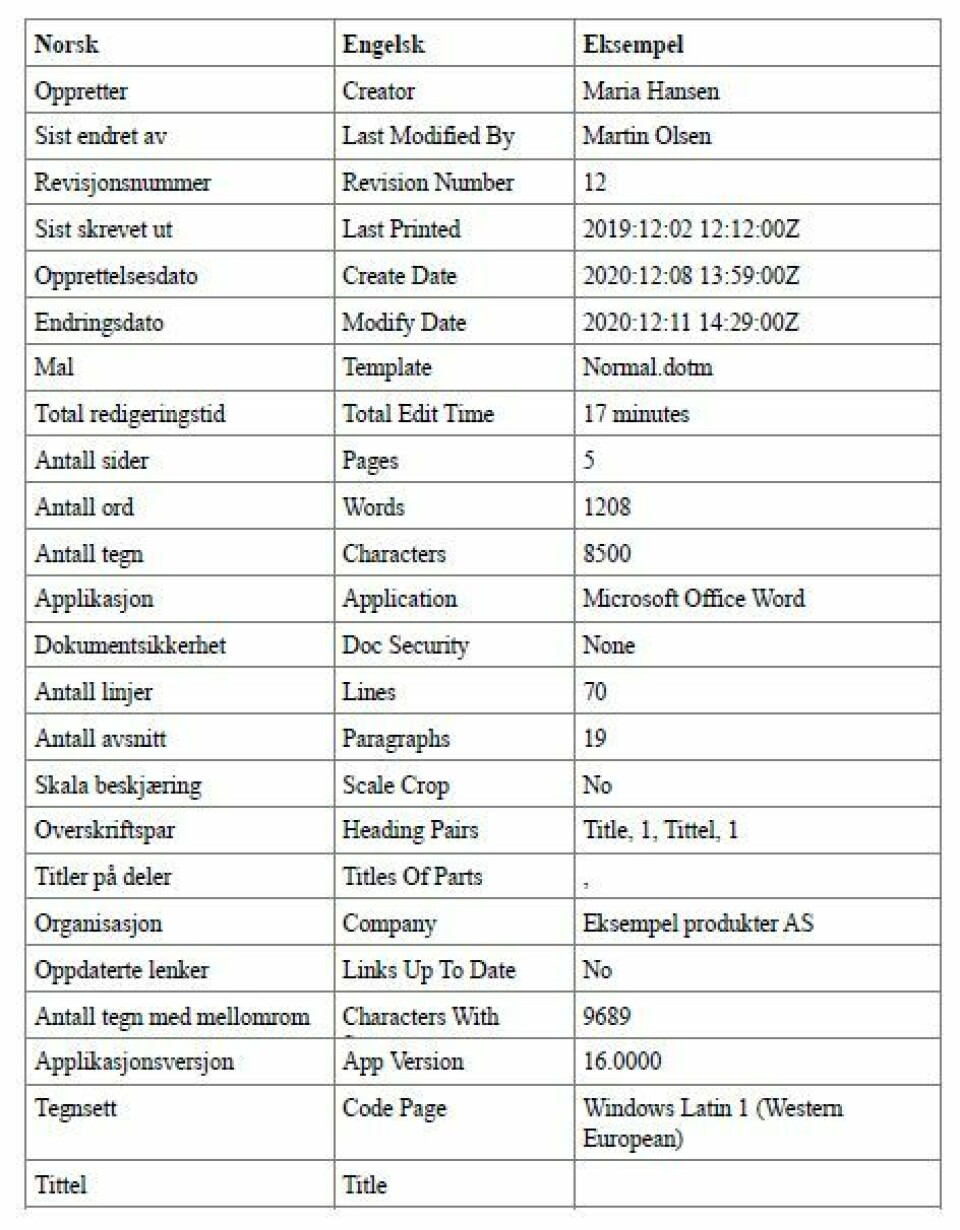
Det som er typisk for disse feltene, er at de sier noe om omfang, hvem som har opprettet og endret dokumentet og når. Tabell 1 forteller oss for eksempel at Maria Hansen opprettet dokumentet, og at det sist ble endret av Martin Olsen. Kan det ha vært flere som har redigert dokumentet? Ja, og det vil ikke nødvendigvis framkomme i disse metadataene. Vi ser bare når dokumentet ble opprettet (2020:12:08), og når det sist ble lagret en endring (2020:12:11). Vi kan også se litt informasjon om omfang, nemlig antall sider, antall ord og antall tegn. I tillegg kan vi se hvilket program som ble brukt til å lage dokumentet, samt versjonsnummer av programmet dersom det er tilgjengelig.
Arkivfaglig verdi?
Hvilken arkivfaglig verdi har så metadata fra slike dokumenter? Arkivverket har tidligere (uformelt) forklart at de ikke anser at slike metadata spiller en viktig rolle i arkivsammenheng. Slike metadata er heller ikke en del av de standardiserte metadataene i Noark-standarden. Men de kan likevel spille en viss arkivfaglig rolle dersom det er ønskelig. I Noark kan feltet «Forfatter» omfavne elementene «Oppretter» og «Sist endret av» i Word. Den som har opprettet eller endret dokumentet, anses som forfatter av dokumentet. Men dette stemmer ikke alltid.
Nylig skulle jeg gjennomgå et tilsynsdokument fra Arkivverket. «Oppretter»-elementet anga navnet til en person som ikke lenger jobbet på Arkivverket, men som antagelig hadde et systemansvar da malen organisasjonen bruker, ble laget. Dokumentet var signert av to personer ved Arkivverket, og flere andre personer som hadde deltatt i tilsynet, var også nevnt i dokumentet. Likevel ble ingen av disse personene identifisert som den som hadde laget eller endret dokumentet.
«Sist skrevet ut» er et annet interessant metadata-element. Hvorvidt et dokument har blitt skrevet ut eller ikke, kan være viktig i en juridisk kontekst for å fastsette hvorvidt det forventes at en person skal ha lest innholdet i et dokument. Nå skriver vi kanskje ikke ut dokumenter i like stort omfang nå til dags¸ så slike metadata har muligens litt mindre verdi. Den observante leser har kanskje lagt merke til en særegenhet i tabell 1, der «Sist skrevet ut»-elementet viser at dokumentet er registrert som skrevet ut før det ble opprettet. Dette er en finurlighet som går igjen med metadata i Word-dokumenter. Antagelig skjer dette når dokumentet bygger på en mal og malen på et tidspunkt har blitt skrevet ut, og at alle dokumenter som opprettes fra malen, har dette metadatafeltet satt.
Når det er en tvetydighet i tolkningen av slike metadata, er det fort gjort å avfeie dem. Men jeg mener at det likevel kan være noe arkivfaglig relevant å hente i slike metadata – blant annet fordi de kan gi et interessant innblikk i bruksperspektivet. Det finnes enkle Word-dokumenter (på under en side med tekst) som har en «Total redigeringstid» på mange timer, samtidig som det finnes Word-dokumenter på 20 sider med en «Total redigeringstid» på mindre enn et par minutter. Slike særegenheter gjør at man fort kan anse slike metadata som irrelevante, men det kan likevel bety noe dersom ektheten til dokumentet er under tvil.
Jeg har selv blitt bedt om å vurdere ektheten til et Word-dokument en journalist fikk tilsendt etter en innsynsforespørsel. Det var et tre siders referat fra et møte som skulle ha funnet sted tre år tidligere. En enkel uthenting av dokumentets metadata viste en «Total redigeringstid» på under et minutt og at dokumentet ble opprettet et par timer etter at journalisten hadde bedt om innsyn. Eksempelet nevnes her fordi metaverdiendata da faktisk kunne si noe om opprinnelsen til dokumentet og kunne brukes for å si noe om autentisiteten. Det er lite troverdig å skrive et slikt referat på under et minutt. Det er med andre ord ikke så sikkert at metadata i dokumenter ikke har en arkivfaglig verdi. Men hvis denne metadataen skal være med i et uttrekk, er det viktig å påpeke at det ligger et usikkerhetsmoment rundt verdiene av disse.
Tap ved konvertering
Hvis man faktisk anser at disse metadataene er viktige, må de også være med når dokumentet konverteres fra produksjonsformat til arkivformat. Dessverre er ikke dette så enkelt, da arkivformatene ikke nødvendigvis har like bra støtte for metadata som produksjonsformatene. Tar vi PDF som et eksempel, ser vi at PDF i utgangspunktet har støtte for et begrenset sett med standardiserte metadata. Tabell 2 viser hvilke metadata-elementer som støttes av PDF. «Oppretter»-elementet refererer til den opprinnelige programvaren som skapte dokumentet, mens «Produsent» peker til programmet som konverterte til PDF. Det er også viktig å vite hvilken programvare som er blitt brukt til konverteringen, for er det en konfigurasjonsfeil, kan det være nyttig å kunne spore opp dokumenter som må sjekkes eller konverteres på nytt.
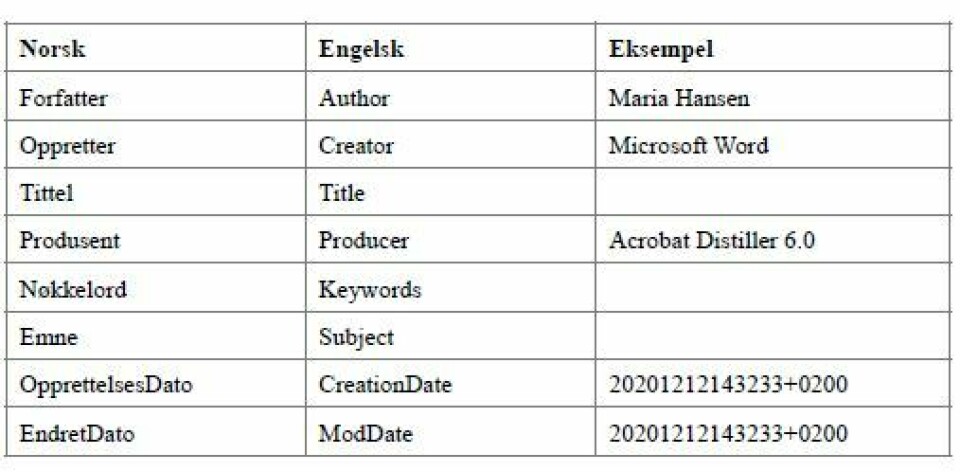
Dato-feltene peker til når PDF-filen ble opprettet og eventuelt endret, men det er viktig å huske at et arkivformat-dokument ikke skal endres, og da kan slike felter skape litt usikkerhet. Noen vil mene at opprettelsesdato og endret dato burde bli satt til verdien fra produksjonsformatet, mens andre vil mene det handler om når PDF-dokumentet ble opprettet/endret. Metadata-elementene tittel, nøkkelord og emne vil tilsvare det som er i Word-dokumentet, dersom de finnes der. Det er lett å se at det er begrenset arkivfaglig verdi i de standardiserte PDF-metadata-elementene.
Det kan reises et spørsmål hvorvidt produksjonsformatets dokumentmetadata skal være med i depot. Det er ikke praksis for dette i dag, og dersom dette kun oppleves som en kuriositet, så er det kanskje ikke bryet verdt. I utgangspunktet vil metadata naturlig bli borte når du konverterer fra produksjonsformat til arkivformat, da det ikke er plass til disse feltene i PDF-metadataene. Listen av metadata støttet i PDF angitt i Tabell 2 viser dette godt.
Bruk av XMP?
Det er også viktig å huske at PDF-metadataene er gjeldende for PDF-dokumentet, ikke produksjonsformatet. Dersom du likevel ser verdien i produksjonsformat-metadataene, er det teknisk mulig å innlemme dem i et PDF-dokument på en annen måte. PDF støtter nemlig også en metadata-standard som heter XMP (Graphic technology — Extensible metadata platform (XMP), ISO 16684-1:2019), som lar deg laste vilkårlige metadata inn i et PDF-dokument. XMP bruker Resource Description Framework (RDF) som underliggende beskrivelsesmetodikk, der RDF beskrives i henhold til XML/RDF-formatet. Dette er et fleksibelt format som tillater markering av metadata som navn/verdi-par, strukturerte verdier eller lister over verdier. Det er relativt enkelt å utvikle slike metadata og ha det som en del av en prosess når dokumenter migrerer fra produksjonsformat til arkivformat. Samtidig er det verdt å merke seg at XMP-standarden er kritisert for å være komplisert og omstendelig. Det er også usikkert hvor utbredt kunnskap om XMP er i det norske arkivmiljøet.
Bruken av XMP er noe som fikk litt oppmerksomhet for noen år tilbake i et lite arbeid som gikk under navnet «Arkivet i dokumentet». Dette handlet om å se nærmere på grenseoppgangen mellom et arkivsystem og dokumentene som forvaltes i arkivsystemet, og det ble utforsket hvor mye metadata fra arkivsystemet det var mulig å overføre til dokumentet. Det viste seg at referanse til arkiv, arkivdel, sak, journalpost og dokumentbeskrivelse er fint mulig å overføre til PDF-filen. Det å innlemme så mye metadata fra arkivsystemet inn i dokumentene er et interessant konsept.
Hvordan hente ut metadata?
Det er forskjellige måter å hente ut metadata fra dokumenter på. Ofte vil det være mulig å se på innbakte metadata i programvaren som skapte dokumentet, men det finnes også tredjepartsverktøy. Et slik verktøy er exiftool. Dette er et fritt programvareverktøy som kan hente ut metadata fra de fleste filtyper.
Dokumentet som utgjør denne artikkelen, ble analysert med exiftool og resultatet vises i tabell 1. I dette tilfellet ble exiftool kjørt som en kommandolinje-applikasjon, men det finnes også grafiske varianter for dem som er mer komfortabel med det.
Verktøyet exiftool kan også, for noen filformater, endre eller slette metadata. Men det er viktig å være klar over at et verktøy som exiftool ikke vil klare å identifisere all metadata. Det kan være mer metadata som ligger skjult i et dokument, og som kan hentes ut i en manuell gjennomgang. Det er ikke snakk om avansert kompetanse for å kunne gjennomføre en manuell inspeksjon av et dokument for skjulte metadata.
Hvordan fjerne metadata
Det kan også være behov for å fjerne, eller sanere, metadata fra et dokument. Et enkelt eksempel på dette er anbefalingen i universitets- og høgskolesektoren om at studenter fjerner selvidentifiserende metadata fra en eksamensinnlevering for å sikre anonym vurdering. Men det finnes mer alvorlige eksempler.
I artikkelen «Exploitation and Sanitization of Hidden Data in PDF Files» fra 2021 ble en samling av 39 664 PDF-dokumenter tilhørende 75 sikkerhetsbyråer fra 47 land analysert. Selv om dokumentene var forsøkt sanert, fant de store mengder personidentifiserende metadata. Eksempelet er betraktelig mer komplekst enn sanering for en eksamensinnlevering, men det reiser et viktig spørsmål; tar organisasjoner sanering av metadata seriøst nok?
Ansvar og autentisitet
Som dokumentasjonsforvalter har du et ansvar for å ha kontroll over metadata i dokumentene dine. Organisasjonen bør ha kontroll over hvilke metadata de tillater å bli eksponert offentlig ved publisering av dokumenter. Det er ikke greit at det er en vilkårlig strategi der dokumenter legges ut uten at den ansvarlige for dokumentasjonsforvaltning vet hvilke metadata som er publisert.
Disse skjulte perlene – metadataene – kan ha si noe om omfang, bruk og autentisitet. Diskusjonen her tilhører et fagfelt som heter «document forensics», et område arkivfagmiljøet burde se nærmere på. Jeg har selv erfart at det er mulig å så tvil om ektheten til et dokument basert på dokumentmetadata, men jeg har også opplevd at slike metadata kan oppleves som unødvendig støy. Det er et vanskelig å gi et enkelt svar på spørsmålet hvorvidt vi skal ta vare på slike metadata, men jeg klarer ikke å slå meg til ro med at dokumentmetadata ikke skal ha en formell plass i organisasjonens bevaringsstrategi.