FORDYPNING

Når «på» blir «pÃ¥» – et reservoar av tegn sett fra depotet
De færreste av oss tenker over hva som skjer dypere i datamaskinen mens vi sitter der og skriver noe på tastaturet. Når du trykker på tasten «Å», så vises bokstaven Å. Men noen ganger blir det feil. Hvorfor det – og hva er viktig å være klar over i arkivsammenheng? Det handler om noe som heter tegnsett.
Dersom bokstaver tolkes forskjellig mellom systemer, blir det fort rot, dette kalles mojibake blant kjennere, etter det japanske uttrykket for tegnomforming. Det er en lang historie her som tidvis har vært preget av rot. Noen husker kanskje tilbake til en tid der bokstavene æ, ø og å ofte var ødelagt i e-poster – et klassisk eksempel på tegnsettproblemstilling.
«Nå» og «før»
Tid er et skjult problem for depot fordi vi danner dokumentasjon i en kontekst som er preget av å være «nå». Vår forståelse av verden og bruken av teknologi er utgangspunktet for denne konteksten. Tenk selv hvordan verden har utviklet seg de siste 20 årene, hva samfunnet er opptatt av, og hvordan vi bruker teknologi i hverdagen. Tid er et skjult problem fordi når vi trekker dokumentasjon ut av systemer og deponerer for langtidsbevaring, er konteksten til materialet «nå», men verden går videre. Ettersom teknologien og måten vi bruker den på, utvikler seg, blir «nå» til «før», og dokumentasjonen befinner seg snart i en «før»-kontekst.
Dette med «før» og «nå» i forhold til dokumentasjonens kontekst er noe vi er veldig lite bevisste på, men det er en problemstilling depotarkivene eier og forvalter. En av disse utfordringene er hvorfor «Ø» ikke nødvendigvis er det samme som «Ø», og hvorfor det i det hele tatt gir mening å si noe sånt. Vi snakker her om noe som heter tegnsett, som er en avtalt måte å representere bokstaver, tall og andre symboler på slik at vi på en feilfri måte kan utveksle tekst mellom datasystemer.
Tegnsettproblemstillingen er satt sammen av fire fasetter; repertoar, representasjon, koding og uttegning.
Repertoarer
Repertoar er en samling med tegn og symboler som kan representeres. Tenk norsk alfabet eller japanske piktogrammer, men også matematiske og elektroniske symboler. Bokstaven «stor a» kan være en oppføring i et slikt repertoar. For å kunne brukes i en datamaskin trenger hver oppføring i et slikt repertoar en representasjon, hvilket i datamaskinsammenheng betyr at det tilordnes et tall. Tallet kan lagres på ulike vis i en eller flere kodingsformater. For eksempel kan en skrive tallet ti som både 10, X og A, i henholdsvis titallssystemet, romertallssystemet og sekstentallssystemet.
Hvis en skal kunne lese inn filer og vite hvilket tall og hvilken representasjon og instans i et repertoar det er snakk om, så må en vite hvordan tallet er kodet. Sist, men ikke minst, for å kunne bruke symbolet til noe må det kunne være kjent hvordan det skal se ut eller tegnes på ark. Det finnes utallige skrifttyper med norske bokstaver, alle litt forskjellige, og skal en kunne tegne en stor A på skjermen, så må datamaskinen vite hva den skal tegne. Skrifttyper inneholder informasjon om hvordan ulike tall skal tegnes. De inneholder ikke alltid alle symbolene som er brukt i en tekst, hvilket gjør at ikke alle forståtte tegn vil kunne vises på skjerm eller ark.
Hver av disse fasettene må være avklart for å kunne ta vare på og vise frem tekst med en datamaskin. Kombinasjon av repertoar, representasjon og koding er det en kaller et tegnsett. Kombinasjonen av representasjon og uttegning kalles en skrifttype. De fleste skrifttyper har også informasjon om repertoar, men det finnes skrifttyper som kun kobler mellom tallkode og uttegning, uten å fortelle noe om hvordan tallkodene egentlig skal tolkes.
Fra ASCII til ISO-8859
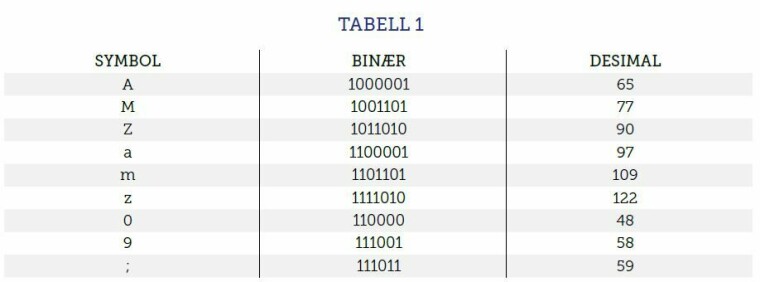
Vi begynner historien med ASCII (American Standard Code for Information Interchange) som har en historie som spores tilbake til 1963. Utgangspunktet til ASCII var at det kunne kode opp til 128 forskjellige symboler i vanlig bruk i USA. De visuelle symbolene i ASCII er de små og store bokstavene (a til z og A til Z), tall (0 til 9) og tegnsettingssymboler (for eksempel semikolon, komma og punktum). ASCII har også noen usynlige symboler som ble brukt for bl.a. kommunikasjon. Før ASCII var det for eksempel teleks-tegnsett med plass til bare 32 tegn og EBCDIC med plass til 256 tegn, alle med en helt annen rekkefølge på symbolene enn ASCII, men de har vært lite brukt de siste femti årene. Et eksempel på noen utvalgte symboler i repertoaret til ASCII vises i tabell 1.
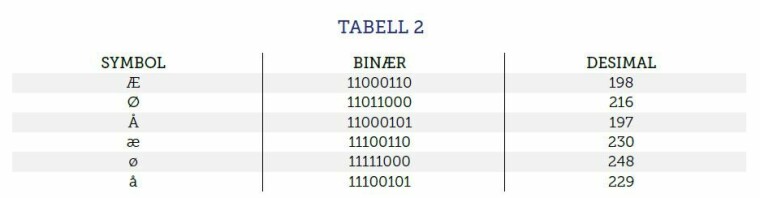
Det opprinnelige ASCII-tegnsettet ble også omtalt som ASCII-7 og brukte 7 bits (0 og 1) for å representere symboler. Datamaskiner er ofte konfigurert til å jobbe med enheter der bits er gruppert som 4 eller 8 bits. Det lå en mulighet i å ta i bruk bit åtte. En slik endring ville gjøre det mulig for datamaskiner å øke antall symboler de kunne representere, noe som ga en økning fra 128 forskjellige symboler til 256 forskjellige symboler. Det ble åpnet for å innlemme de nordiske bokstavene sammen med ASCII, og dette ble etter hvert standardisert som ISO-8859-1. Tabell 2 viser deler av ISO-8859-1 som støtter de norske bokstavene.
Det sier seg selv at muligheten til å representere inntil 256 symboler ikke holder når vi snakker om en global verden, og det ble gjort et standardiseringsløp som tok utgangspunkt i ASCII-7 med en utvidelse til å bruke den åttende biten for ulike språkgrupper. Denne standarden heter ISO-8859 og er inndelt i opptil 16 varianter, altså fra ISO-8859-1 til ISO-8859-16.
Norske tegn er definert i ISO-8859-1, som også omtales som Latin 1, de fleste samiske tegn er definert i ISO-8859-4 (Latin 4) mens tilgang til €-symbolet kom med ISO-8859-15 (Latin 9). ISO-8859-15 er en revisjon av ISO-8859-1 som fjerner noen lite brukte symboler og erstatter bokstaver som er mer brukt, og introduserer €-symbolet.
Det er viktig å merke at alle ISO-8859-variantene har overlapp med ASCII-7, noe som ga samvirke med de engelskspråklige landene som ikke trengte å gjøre noe. Det innebærer også at de første 128 verdiene i ISO-8859-variantene representerer de samme symbolene. Det er først når du kommer til tolkningen av de resterende 128 verdiene med nummer 128 til 255, at det oppsto tolkningsutfordringer mellom ISO-8859-variantene.
ISO-8859-verdenen fungerte godt så lenge tegnsettet som ble brukt når innhold ble skapt, også ble brukt når innhold ble gjengitt og du ikke trengte å kombinere innhold fra forskjellige tegnsett i samme dokument. Utfordringen med bruken av ISO-8859-variantene ble raskt tydelig i en mer globalisert verden med utveksling av tekst på tvers av landegrenser der tekstlig innhold i dokumenter, e-poster og websider kunne bli skrevet med ett tegnsett og gjengitt med et annet tegnsett.
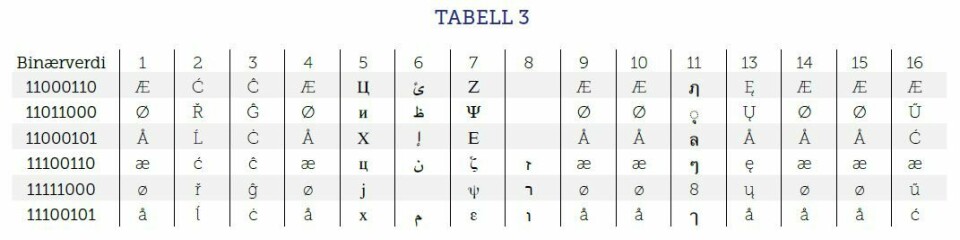
Denne problemstillingen er illustrert i tabell 3, der vi ser verdiene tilegnet de norske symbolene i ISO-8859-1 i kolonne «1». I de øvrige kolonnene ser vi hvilket symbol verdien får i de andre ISO-8859-variantene. Tar vi utgangspunkt i tabell 3, kan vi se at ordet lærlingspørsmål gjengitt med ISO-8859-2 (kolonne 2) blir lćrlingspřrsmĺl, mens det blir lζrlingspψrsmεl med ISO-8859-7 (kolonne 7). Med ISO-8859-2 blir «æ» til «ć», «ø» til «ř» og «å» til «ĺ». I ISO-8859-7 blir «æ» til «ζ», «ø» til «ψ», mens «å» blir «ε».
Det er egentlig ingen utfordring med dette så lenge du vet hvilket tegnsett innholdet ditt er representert med, og det ikke har skjedd omforminger som du ikke er klar over. Det er det siste som er problematisk, spesielt de datasystemene som har vært i bruk de siste 20 årene, som ikke har noe innebygd funksjonalitet for å forvalte tegnsettproblematikken. Et godt eksempel på dette er Microsoft-tegnsettet Windows-1252, som ble forvekslet som 100 % kompatibel med ISO-8859-1, men hadde byttet ut plassene fra 127 til 159. Historisk vil det finnes en del variasjon i hvilket tegnsett som har vært i bruk, og hvor vellykket konvertering mellom tegnsett har vært.
Unicode
som løsning
Tegnsettforvirring ble etter hvert et irritasjonsmoment og samvirkeproblem. Ofte fikk man en e-post der æøå var erstattet av rare symboler fordi e-posten hadde vært innom et eller annet datasystem som ikke brukte samme tegnsett.
For å løse dette samvirkeproblemet for tegnsett ble det startet et arbeid og en ny standard så dagens lys etter hvert. Denne standarden fikk navnet Unicode (ISO/IEC 10646) og skulle resultere i et tegnsett som alle skulle være enige om. Unicode er et repertoar og en representasjon, dvs. navngivning og tilordning av tallverdi til alle symboler i bruk i verden i dag.
Oppføringer i Unicode skrives gjerne U+XXXX der XXXX er tallkoden i sekstentallssystemet som oppføringen har i Unicode-katalogen. Her finner vi tegn brukt av både levende og døde språk, konstruerte språk, tekniske symboler, morsomme tegninger (såkalte emojier) og tegn ingen vet hva betyr eller skal brukes til. Et morsomt eksempel er u+237c ⍼ right angle with downwards zigzag arrow, av Jonathan Chan.
Sammen med Unicode kom det tre måter å kode disse tallene på; UTF-8, UTF-16 og UTF-32. Av datatekniske årsaker er UTF-8 mye brukt, spesielt når det gjelder utveksling av tekst over Internett, mens UTF-16 er brukt en del til tekstfiler lagret på Windows. En utfordring med Unicode og UTF-variantene er at disse gir flere måter å kode samme symbol på med en kombinasjonsmekanisme. Dette kan gi utfordringer ved søk, hvis en skal søke etter et ord som har ett eller flere symboler som kan skrives på ulikt vis, så er det ikke sikkert at søkesystemet vil finne alle forekomster. For eksempel kan bokstaven U+00F8 «Latin Small Letter O with Stroke» kodes som den tradisjonelle norske tegnet ø, men også som o kombinert med skråstrek U+0338. Begge deler er gyldig bruk av Unicode, selv om det er tradisjon for å foretrekke å «normalisere» kombinasjoner som enkelttegn der det er mulig, nettopp for å forenkle søk.
Få systemer har automatikk for å fange opp slike ødeleggelser når tekstlig innhold utveksles mellom datasystemer. Det finnes automatikk for å oppdage slikt, men det er lite brukt.
Bare Unicode fremover
Forvaltningens bruk av tegnsett er regulert i Forskrift
om IT-standarder i offentlig forvaltning. Her står det: «Ved all utveksling
av informasjon mellom forvaltningsorganer og fra forvaltningsorgan til
innbyggere og næringsliv skal tegnsettstandarden ISO/IEC 10646 representert ved
UTF8 benyttes.»
Det er forskjellige bruksområder til UTF-8, UTF-16 og UTF-32, men UTF-8 er kodingen vi kjenner mest til. Det er flere grunner at UTF-8 «vant» konkurransen til å bli den utvalgte. Den kanskje viktigste er at UTF-8 er fullt samvirkende med ASCII-7, slik at den engelskspråklige delen av verden kunne rulle ut UTF-8 uten å merke noe forskjell. En tekstfil med kun ASCII-tekst vil være identisk på disken hvis den lagres som UTF-8 og ASCII. UTF-16 og UTF-32 byr på noen optimaliseringer som gjør dem relevant for spesifikke problemområder, men for det meste vil vi aldri oppleve disse standardene på nært hold i hverdagen. Det er uansett kun bruken av UTF-8 som er lovregulert i Norge.
Det er ikke slik at hele verden bruker ISO/IEC 10646 og UTF-8. Kina har egne standarder for tegnsett, mye brukt er GB 18030, som er Unicode med en annen koding enn UTF-8, mens Taiwan og andre asiatiske land gjerne bruker Big5 eller andre tegnsett.
UTF-8 er dominerende i Norge, men det er tidsperioder der forskjellige datasystemer utvekslet data i henhold til ISO-8859-1, ISO-8859-15, Windows-1252, Codepage 865 og ISO-646-60 / Codepage 1016 mens overgangen til UTF-8 pågikk. Det er ikke slik at et datasystem enkelt kan tvinges til å bruke et tegnsett, da det er flere lag i et datasystem som må settes opp til å bruke riktig tegnsett, og tegnsettproblemet fort oppstår når det er et eller annet i datasystemet som bruker feil tegnsett.
Et klassisk eksempel på problemet er en utveksling av tekst mellom to systemer der teksten i utgangspunktet er kodet i UTF-8, men går gjennom noe som er ISO-8859-1 underveis. Dette kan vises med at ordet «på» i et slik scenario ender opp som «pÃ¥». Det er mulig å spore dette tilbake til verdiene symbolene er tilordnet i tegnsettene. «på» blir til «pÃ¥» fordi «å» i UTF-8 er representert med U+C3AF, og dersom vi ser på hva disse verdiene representerer, ser vi at sekstentallssystemverdien C3 er 1100 0011 i totallssystemet og symbolet med dette tallet i ISO-8859-1 er Ã.
Vi ser det samme med sekstentallssystemverdien A5, som er 1010 0101 i totallssystemet, og tilsvarende symbol i ISO-8859-1 er ¥. Slik mojibake kan lett skje hvis «på» i utgangspunktet var representert med UTF-8, men ble behandlet med et system som bruker ISO-8859-1. Det er ingen automatikk i å fange opp slike ødeleggelser mens tekstlig innhold utveksles mellom datasystemer.
En utfordring for depotarkivene er at bruken av tegnsett ikke alltid har vært regulert, og at det kan finnes flere dokumentasjonssamlinger som er opprettet med varierende tegnsett før gjeldende forskrift inntraff – uten at det er mulig å avlede fra filene hvilket tegnsett som ble brukt. Et eksempel på dette er €-symbolet, som kom først etter at ISO-8859-1 var tatt i bruk. Det kan bli en utfordring for et depotarkiv, men så lenge det er kjent hvilket tegnsett var i bruk, så bør det gå bra.
Riksarkivarens forskrift
Riksarkivarens forskrift formaliserer dette ved å kreve følgende:
§ 5-11. Tegnsett i arkivuttrekk
(1) Arkivuttrekk og medfølgende struktur- og innholdsbeskrivelser skal overføres som ren tekst i ukryptert form, og benytte godkjent tegnsett.
(2) Godkjente tegnsett er:
a. Unicode UTF-8 (ISO/IEC 10646-1:2000 Annex D)
b. ISO 8859-1:1998, Latin 1
c. ISO 8859-4:1998, Latin 4 for samiske tegn.
(3) Andre tegnsett aksepteres bare etter avtale med Arkivverket.
Som danningsarkivar har du et ansvar for å vite hvilket tegnsett systemene og databasene dere forvalter, er i samsvar med.
Ditt ansvar
På mange måter burde ikke tegnsett være et problem i 2023, men sånn er det nok ikke. Land som har oppgradert til UTF-8 som primærtegnsett for utveksling av tekstlig innhold, begrenser problematikken betraktelig, men globalt sett så er tegnsettutfordringen ikke løst fordi ikke alle er enige om å bruke samme tegnsett. Det kan være geopolitiske eller kulturelle hensyn som ligger til grunn for dette.
Det er uansett verdt å merke at selv om bruken av UTF-8 skulle bli 100 % utbredt, så er det et historisk perspektiv (ASCII-7, ISO-8859-variantene, UTF-8) her som gjør tegnsett til et problemområde arkivarene må forstå og håndtere.
Som danningsarkivar har du et ansvar for å vite hvilket tegnsett systemene og databasene dere forvalter, er i samsvar med. Det er noe IT-avdelingen din eller programvareleverandørene enkelt skal kunne svare på, og svaret skal være UTF-8 for alle nye systemer.